



Photo by Markus Spiske on Unsplash
In the previous article, we learned the theoretical concepts of Generative Adversarial Networks.
In this article, we’ll understand how to implement Generative Adversarial Networks in Tensorflow 2.0 using the MNIST dataset of digits. Our model should be able to accurately create images similar to MNIST dataset images. Image from MNIST dataset looks like this:
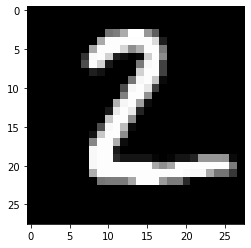
Before moving ahead please make sure you are updated with the following requirements:
For implementing the network, we need to follow the following steps.
We will need to import these libraries.
In this piece of code, we imported data and reshaped it. Images are represented in the values between 0 to 255. So these image vectors are converted into values between [-1, 1]. Then these vectors are shuffled and converted to batches of 256 images.
The generator model will take vector of 100 pixels as input and convert that vector into an image of 26 * 26 using the Conv2DTranspose layer. As we are using convolutions, this model will be a DCGAN i.e. Deep Convolutional Generative Adversarial Network.
BatchNormalization layer is used for normalizing the generated image to reduce noise that image. The activation function of “ReLU” is added as another layer in the model.
Discriminator will do the exact opposite of a generator and convert image into scalar probabilities of whether the image is fake or real. It will use the Conv2D layer for this purpose. Along with the convolutional layer, it will have layer of an activation function “ReLU” and the Dropout layer.
After both the models are created, we’ll move to the next steps.
Here, we’re using BinaryCrossentropy from tf.keras.losses API. Using this cross_entropy loss, we’ll make loss functions for discriminator and generator.
Now, we’ll create optimizers for generator and discriminator using Adam optimizer from tf.keras.optimizers API with a learning rate of 1e-4.
Initially, the generator will generate an image with only random pixels and as time passes, it will make images that are almost similar to the training images. Image from the generator before training looks like the following:

First, we need to create noise data for passing into the generator model. Then create a function to learn through iterations using the concept of Eager Execution. Please refer to this video for understanding what is Eager Execution as it is out of scope for this tutorial.
GradientTape above is used for creating gradients as we go further and these gradients are applied to optimizers for decreasing the loss function.
This is the final function to call the train_step function for each batch in the dataset.
Finally, we’ll call our train_GAN function to start training on the image dataset with 500 epochs.
After going through all the epochs, the generated image looks like this:

Let’s look at the results in the form of GIF.

It could be seen how our neural networks learn to write integers like a child. We can use the same algorithm for multiple image generators because we only need to change the training images and train again.
GANs could be used for many more domains other than images with the same concept of Generator and Discriminator. Also, read – Contrasting Model-Based and Model-Free Approaches in Reinforcement Learning.













